













Kinijos rinka dar kartą primena apie sparčiai tobulėjančius savo sprendimus DI lenktynėse.
Kinijos dirbtinio intelekto modelis „Qwen-3 Max“ pranoko „ChatGPT“ ir „Gemini“
TRUMPAI
- • „Qwen-3 Max Thinking“ svarbiuose testuose aplenkė „ChatGPT“ ir „Gemini“.
- • Modeliui pranašumą suteikia pažangūs mąstymo metodai ir įrankių integracija.
- • Rezultatai rodo spartų Kinijos DI konkurencingumo augimą.
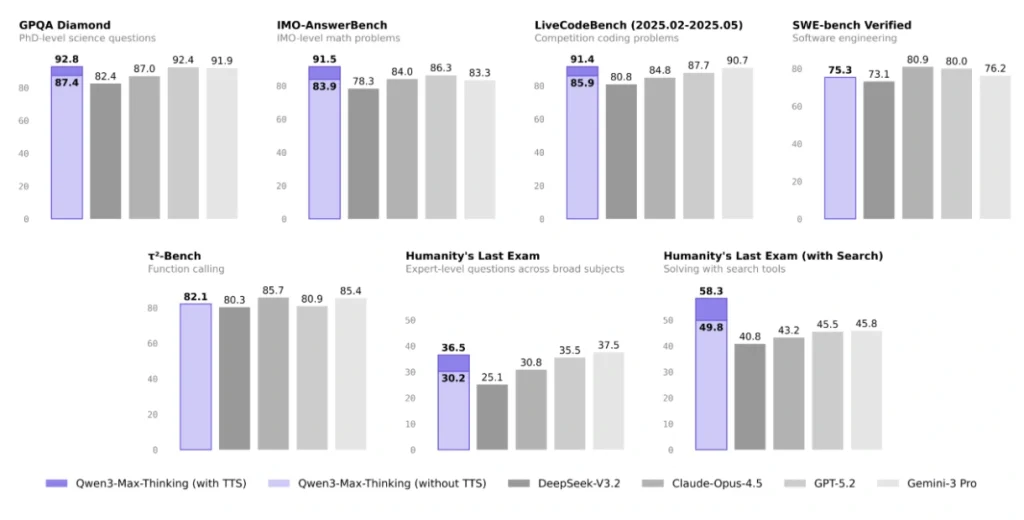
Kinijos technologijų milžinės „Alibaba“ dirbtinio intelekto (DI) komanda pristatė naujausią „Qwen-3 Max Thinking“ modelio versiją. Remiantis naujausiais testų rezultatais, kai kuriose konkrečiose užduotyse ji pranoksta tokius konkurentus kaip „OpenAI“ „GPT-5.2“ ar „Google Gemini 3 Pro“.
REKLAMA
„Qwen-3 Max Thinking“ modelio stiprybės
Pažangus Kinijos kalbos modelis sukurtas su milijardo parametrų mišria architektūra ir apmokytas milžinišku kiekiu duomenų – daugiau nei 36 trilijonais žetonų.
Modelis gali automatiškai integruoti išorinius įrankius, pavyzdžiui, interneto paiešką, taip sumažindamas vadinamųjų „haliucinacijų“ skaičių. Tačiau pagrindinė jo stiprybė atsiskleidžia taikant „Test-Time Scaling“ metodą – jo metu modelis atlieka kelių lygių gilų mąstymą, kuris leidžia tiksliau ir nuosekliau spręsti sudėtingas užduotis, tokias kaip programavimo ar aukšto lygio matematiniai klausimai.
Rezultatai „Humanity’s Last Exam“ ir kituose testuose
Nepriklausomi testai rodo, kad „Qwen-3 Max Thinking“ pasiekė labai gerus rezultatus vadinamajame „Humanity’s Last Exam“ teste. Tai sudėtingas testų rinkinys, skirtas patikrinti, kaip DI modeliai susidoroja su sudėtingomis, akademinių žinių reikalaujančiomis užduotimis.
Šiame teste „Qwen-3 Max Thinking“ surinko 49,8 proc. teisingų atsakymų ir aplenkė tiek „Gemini 3 Pro“ – 45,8 proc., tiek „GPT-5.2 Thinking“ – 45,5 proc.
Be minėto testo, modelis taip pat gerai pasirodė programavimo ir matematikos užduotyse. Aukšti rezultatai kituose testuose rodo, kad „Qwen-3 Max Thinking“ geba efektyviai spręsti tiek techninius, tiek akademinius klausimus ir gali konkuruoti su pažangiausiais šiuo metu rinkoje esančiais DI modeliais.
REKLAMA
Ar kartojasi „DeepSeek“ „momentas“?
„Qwen-3 Max Thinking“ rezultatai neišvengiamai primena „DeepSeek“ proveržį praėjusiais metais, kai Kinijoje sukurtas DI modelis netikėtai pasiekė likusio pasaulio technologijų milžinų lygį.
Kaip ir tada, testų duomenys rodo, kad Kinijos DI ekosistema geba sparčiai kurti konkurencingus modelius, ypač tobulinant mąstymo metodus ir efektyvų skaičiavimo resursų naudojimą.
Visgi tikrasis proveržis bus matomas vėliau – pavieniai testai rodo pažangą, tačiau kur kas svarbiau išlieka ir ilgalaikis modelio pritaikomumas ir konkurencingumo palaikymas dinamiškoje aplinkoje.
Plačiau apie pasaulinio dėmesio ir daug parsisiuntimų sulaukusį „DeepSeek“ skaitykite čia.
Kaip vertinate šį straipsnį?
NAUJIENOS IŠ INTERNETO
Prenumeruokite mūsų „YouTube“ kanalą ir mėgaukitės įdomiais vaizdo reportažais apie mokslą ir technologijas.






Trumpai, aiškiai ir be triukšmo – gaukite svarbiausias technologijų ir mokslo naujienas pirmieji.
1 700+ narių jau seka mūsų puslapį, laukiame tavęs!
DIENOS SKAITOMIAUSI
1
3 ženklai, kurie išduoda apgaulingą el. laišką
2Mokslininkai paprašė DI sukurti biologinį ginklą – tai, ką gavo, sukėlė nerimą
3Pompėjoje DI atkūrė per Vezuvijaus katastrofą žuvusio vyro veidą: naujas požiūris į praeitį
4Eidamas 79-uosius metus mirė žmogaus DNR iššifruoti padėjęs J. Craigas Venteris
5Visur jungiatės per „Google“ paskyrą? Štai kokie pavojai gali slypėti
NAUJAUSI



10
Taip pat skaitykite
Atrinkome panašius straipsnius, kurie gali jums patikti.

Dirbtinis Intelektas
Kaip gauti geresnius DI atsakymus: 5 paprastos taisyklės
Agnė | 2026-05-01

Dirbtinis Intelektas
DI skubios pagalbos diagnozėse aplenkė gydytojus: kaip keisis gydymo kokybė
Agnė | 2026-05-01

Mokslas Ir It
Pompėjoje DI atkūrė per Vezuvijaus katastrofą žuvusio vyro veidą: naujas požiūris į praeitį
Rokas | 2026-04-30

Išmanieji Įrenginiai
„Galaxy S26“ DI funkcijos gali pasiekti šiuos senesnius „Samsung“ telefonus
Agnė | 2026-04-30

Dirbtinis Intelektas
Mokslininkai paprašė DI sukurti biologinį ginklą – tai, ką gavo, sukėlė nerimą
Agnė | 2026-04-30

Dirbtinis Intelektas
DI lūžis jau arti: įvardijo, kada gali priartėti prie žmogaus sąmonės
Agnė | 2026-04-29

Dirbtinis Intelektas
Tyrimas: kas trečia nauja svetainė sukurta DI – ar galima jomis pasitikėti?
Agnė | 2026-04-28

Išmanieji Įrenginiai
„Apple“ ruošia 6 visiškai naujus įrenginius: štai kas laukia
Rokas | 2026-04-24

Dirbtinis Intelektas
Didžiausi DI mitai, kuriais vis dar tiki žmonės
Agnė | 2026-04-24
Dirbtinis Intelektas
Kas yra dirbtinis intelektas? Išsamus gidas 2026
Rokas | 2026-04-28